临床科研必读:临床组学研究中样本量估算和500篇论文样本量统计
阅读:5196
时间:2024-12-09
在临床研究中,样本量的充足不仅直接关系到研究结果的可靠性和外推性,更是决定研究成果能否登上高影响力期刊的关键因素。随着组学技术在临床研究中广泛应用,我们逐渐意识到,传统流行病学样本量计算方法在面对临床组学研究时显得力不从心。那么,我们应该如何估算样本量呢?
今天小谱为您介绍两种好用的方法:一是基于统计模拟的经验估算法,二是利用软件工具基于效应指标的样本量计算法。除此之外,小谱还吐血收集并整理了500篇最新文献,揭示了不同论文分区和影响因子下的样本量分布情况,展现了样本量与论文质量之间的相关性,供大家参考。
一、预测模型的样本量估算
在临床研究中,组学大数据常被用来构建疾病的预测模型。这类研究往往需要一定数量的样本用于模型的构建,还需要另一部分样本来验证模型的有效性。下面为大家分别介绍构建模型和验证模型阶段样本量的估算方法。
01
构建预测模型的样本量估计
基于统计模拟的经验估计样本量的方法:可以采用EPV(Events Per Variable)策略[1,2],常见的做法是遵循10EPV原则,即预测模型中每纳入一个预测变量,至少需要10个事件[3]。以结直肠癌诊断生物标志物的研究为例,如果最终的模型希望纳入5个预测变量,那么实验组则至少需要50个样本。另外如果实验组和对照组采用1:1匹配比例,对照组也需要收集50个样本,因此整个研究共需要收集100个样本,才能满足样本量的要求。
基于效应指标估计预测模型的样本量:需要满足4个要求[4-6]。
● 总体结果风险或平均结果值的估计精度:样本量大小要能够准确估计整个研究人群中事件发生的概率或连续变量的平均值。
● 对所有个体具有较小平均误差的预测值:样本量大小要能确保模型对每个个体的预测误差最小。这通常涉及到预测变量的数量和目标人群中预期结果的发生率。
● 模型表现的收缩大于预定标准:样本量大小要能助于降低过拟合的可能,确保模型在新数据上的表现接近其在训练数据上的表现。
● 模型拟合的高估值小于预定标准:样本量大小能保证模型的预测性能与最优可能模型的性能之间的差异最小。
基于上述要求依次进行样本量计算可能较为复杂。在实际操作中可以直接使用PASS软件或R语言进行计算。PASS软件界面友好、操作简便,用户只需要确定研究设计方案,并提供相关信息,就可以通过简单的菜单操作估计所需的检验功效和样本量。
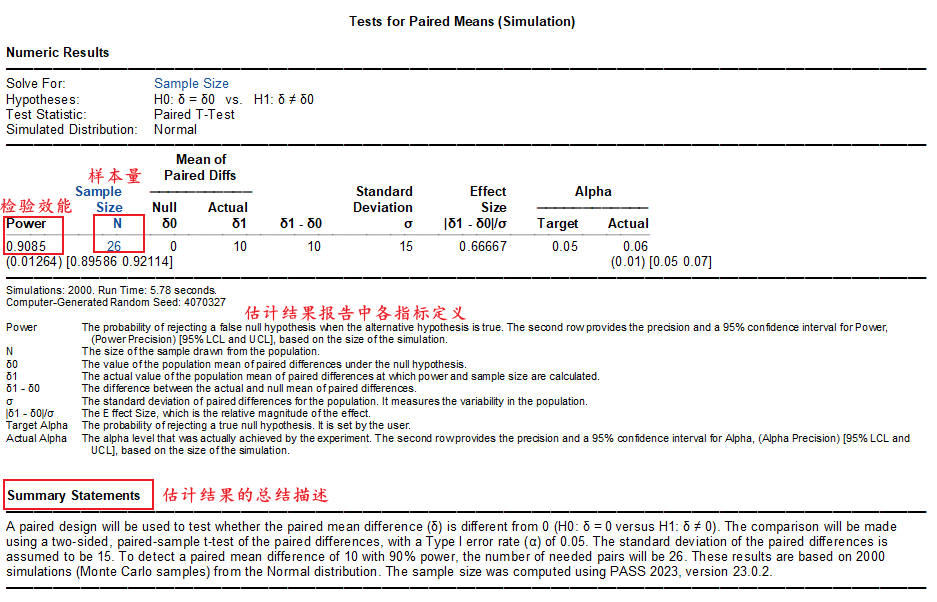
图1 PASS样本量估算结果图
图1展示了一项基于PASS软件进行配对设计研究的样本量估算结果。该结果基于配对差值的均值、标准差、检验水准(α=0.05)以及检验效能(1-β=0.9),最终得出样本量为26例。报告结果展示清晰,并配有相应注释,易于理解和应用。
对于有更严格要求的样本量估算,可以使用R工具Pmsampsize1中的 pmsampsize 函数来计算样本量[7]。该R包可用于计算连续变量、二分类变量或生存结局(时间-事件)的模型构建时所需的最小样本量,并允许根据不同的变量类型选择不同的参数进行计算。
02
验证预测模型的样本量估计
经验估计法:根据模拟和重采样研究的结果,目前已经形成了一套经验估计方法,用于计算模型验证阶段所需的样本量。对于单中心外部验证研究,建议至少收集100例阳性事件和100例非阳性事件,以确保对模型性能指标的准确估计;对于多中心外部验证研究,每家中心应至少有50例阳性事件。如果研究目标是需要得出一个合适的校准曲线时,那么验证模型就需要更大的样本量,至少需要200例阳性事件和200例非阳性事件[8],以确保模型验证的准确性和可靠性。
基于效应指标的计算方法:预测模型验证中,不同结局变量类型的样本量估计需要计算不同的指标。当研究结局为连续变量时,需要基于四个关键指标(R²、平均校准度、校准斜率和结局的方差)来评估模型性能[9,10],并分别估算模型外部验证所需的最小样本量[11]。最终验证模型所需的最小样本量应取4个样本量估算值中的最大值。
在这里我们以关键指标R²为例。R²(R-squared),也称为决定系数,是衡量一个统计模型预测能力好坏的指标,可用于模型样本量估算。例如,某一研究使用了两个变量作为预测变量,分别是年龄和孕早期流产的数量。该研究模型预估的R²值为0.1089,预期收缩率为0.9,流产发生率预计为35%。通过R包pmsamsize计算,则该预测模型所需样本量为350例[12]。
在预测模型的样本量估计中,还涉及到一些函数相关代码的具体使用方法和关键指标的统计方法,若想对这部分内容进一步了解,可以通过扫描文末二维码获取更多信息哦~
二、临床蛋白质组学论文中样本量统计结果概览
蛋白质组学技术已成为各类期刊、基金资助以及临床研究的热点。临床蛋白质组学领域的相关论文数量近年来持续增长,且隐隐有着样本量逐渐增大的趋势。为了了解不同档次论文对于样本量的要求,小谱搜集并分析了近几年发表的500篇参考论文,并分别以不同JCR分区(表1)、不同影响因子(表2)、不同分区+影响因子(表3)三个表格直观展示各自的样本量范围、样本量中位数及验证所需样本量的统计数据。
表1 不同分区中论文样本量数据展示

表2 不同影响因子中论文样本量数据展示

表3 不同分区及影响因子中论文的推荐样本量展示
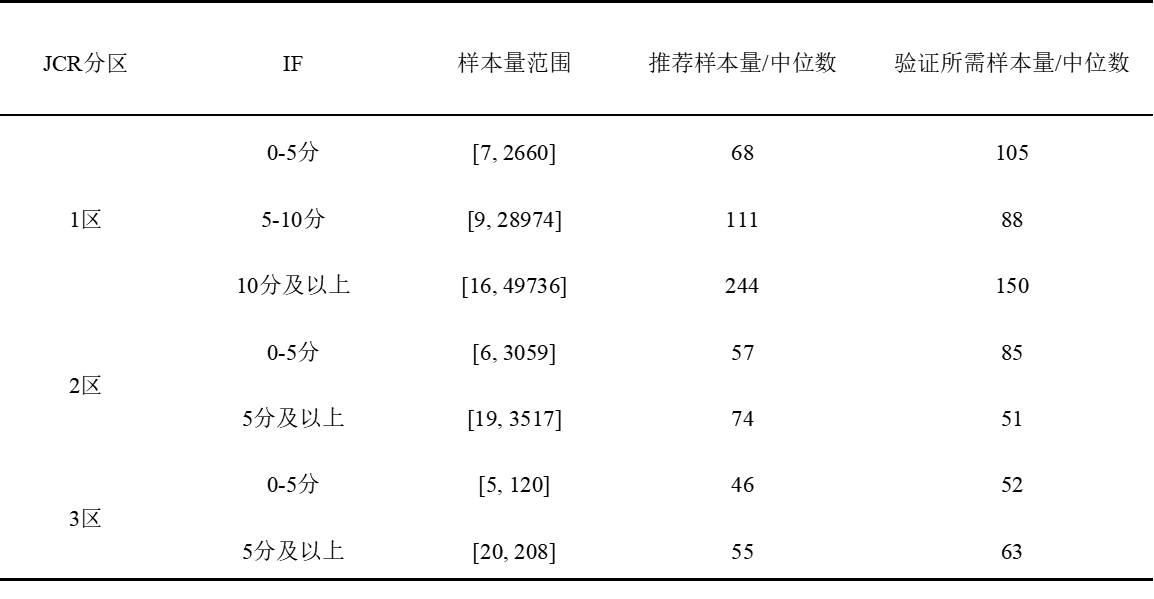
根据统计结果发现,论文中的样本量差异非常大,从几十个样到数百甚至数千个样本不等。但整体上期刊的分区越好,影响因子越高,其所需样本量也就越大。如果希望研究结果能在一区10分以上的期刊发表,可能需要200-300例样本进行研究,后用100-200例样本进行验证。当然由于整个研究中蛋白质组学占比的不同,有时少量的样本也能满足要求(如表3,16例样本),但此类文章往往需要增加很多其他的研究结果。这些统计数据可以为大家提供一个参考,具体来说还是需要大家根据目标期刊的影响因子和分区来估计所需的样本量。
但一味的追求样本量,并不能保证文章可以发表的很好,因为研究选题的价值和创新性、设计方案的科学性、数据的质量、分析方法和验证方法的有效性,都是重要的影响因素。以我们团队近年的研究经验来看,要满足模型构建分析的最低需求,每组至少需要收集15例样本。
我们这次调研的文献有500篇之多,覆盖了消化科、内分泌科、皮肤科、妇产科、眼科、精神科、口腔科和传染科等多个专科中蛋白质组学的临床科研应用。充分展示了蛋白质组学技术应用的广泛性,从生物标志物的探索、疾病的精确分型、预后评估,到深入的分子机制研究,预测模型的构建等。其中不乏大量具有代表性的文章,可以帮助研究人员更好的理清研究思路。小谱在这里也无偿的分享给大家,可以通过扫码文末的二维码获取哦~
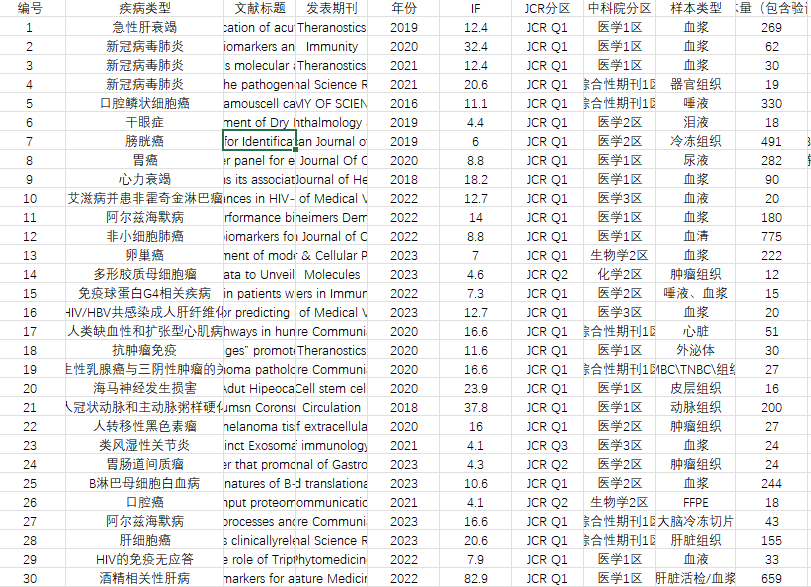
图2 样本数量调研结果表
三、结语
充足的样本量对于研究结果的可靠性和说服力至关重要。然而在考量论文发表的分区和影响因子时,我们应当认识到这不仅仅是样本量的简单累积,而是一个涉及多维度考量的复杂结果。想要发表高质量文章,首先研究的创新性是核心,它体现了研究对现有知识体系的扩展和贡献。其次,研究质量、深度以及对学科领域的贡献也是关键因素,它们共同塑造了论文的学术价值和影响力。只有在选择期刊投稿时综合考虑这些因素,才能确保论文的发表既符合学术要求,又能实现最大的影响力。

















